26 января 2024
Как мы автоматизировали конвертирование проектов C# в C++: Часть 2
Разработка
Разработка транслятора кода с C# на C++ были полностью выполнены компанией CodePorting. Работа потребовала многочисленных исследований, применения различных подходов и тестирования, учитывая модель памяти и другие аспекты. В итоге были выбраны два решения. Одно из них в настоящее время используется для выпуска продуктов Aspose для C++.
Технологии
Настало время поговорить о технологиях, используемых в проекте. Портер представляет собой консольное приложение, написанное на языке C#, поскольку в таком виде его проще встраивать в скрипты, выполняющие задачи типа «портировать-скомпилировать-прогнать тесты». Кроме того, имеется GUI-компонент, позволяющий достигать тех же целей щелчками на кнопках.
Анализ синтаксиса в устаревшем поколении транслятора выполняется с помощью библиотеки NRefactory, а в новом – с использованием Roslyn.
Транслятор использует проходы по AST-дереву для сбора информации и генерации выходного кода на C++. При генерации кода C++ AST-представление не создаётся, и весь код сохраняется в виде простого текста.
Во многих случаях транслятору требуется дополнительная информация для тонкой настройки. Такая информация передаётся ему в виде опций и атрибутов. Опции применяются ко всему проекту сразу и позволяют задать, к примеру, имена макросов экспорта членов классов или определения препроцессора C#, используемые при анализе кода. Атрибуты навешиваются на типы и сущности и определяют обработку, специфичную для них. Например, необходимость генерации ключевых слов const или mutable для членов классов или исключения их из трансляции.
Классы и структуры C# транслируются в классы C++, их члены и исполняемый код транслируются в ближайшие эквиваленты. Generic-типы и методы отображаются на шаблоны C++. Ссылки C# транслируются в умные указатели (сильные или слабые), определённые в Библиотеке. Более подробно о принципах работы транслятора будет рассказано в отдельной статье.
Таким образом, исходная сборка C# преобразуется в проект на языке C++, который вместо библиотек .NET зависит от нашей общей библиотеки. Это показано на следующей диаграмме:
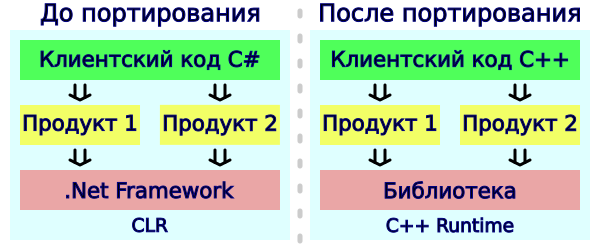
Для сборки библиотеки и транслированных проектов используется Cmake. На данный момент поддерживаются компиляторы VS 2017 и 2019 (Windows), GCC и Clang (Linux).
Как было сказано выше, большинство наших реализаций .NET представляют собой тонкие прослойки над сторонними библиотеками, выполняющими основную работу. Это включает в себя:
- Skia — для работы с графикой;
- Botan — для поддержки функций шифрования;
- ICU — для работы со строками, кодировками и культурами;
- Libxml2 — для работы с XML;
- PCRE2 — для работы с регулярными выражениями;
- zlib — для реализации функций сжатия;
- Boost — для различных целей;
- несколько других библиотек.
Как транслятор, так и библиотека покрыты многочисленными тестами. Тесты библиотеки используют фреймворк GoogleTest. Тесты транслятора написаны, в основном, на NUnit/xUnit и разбиваются на несколько категорий, удостоверяя, что:
- вывод транслятора на данных входных файлах совпадает с целевым;
- вывод конвертированных программ после их компиляции и запуска совпадает с целевым;
- тесты NUnit из входных проектов успешно преобразуются в тесты GoogleTest в конвертированных проектах и проходят;
- API конвертированных проектов успешно работает в C++;
- влияние отдельных опций и атрибутов на процесс трансляции соответствует ожидаемому.
Для хранения исходного кода мы используем GitLab. В качестве среды CI выбран Jenkins. Конвертированные продукты доступны в виде пакетов Nuget и в виде архивов для скачивания.
Проблемы
Во время работы над проектом нам пришлось столкнуться с большим количеством проблем. Одни из них были ожидаемы, тогда как другие проявились уже в процессе. Коротко перечислим основные из них:
- Различия в системе типов между .NET и C++.
Начнём с того, что в C++ нет аналога типаObject, а для большинства библиотечных классов отсутствует RTTI. Одно это уже ставит крест на возможности напрямую отобразить типы .NET на типы STL. - Высокая сложность алгоритмов трансляции.
В то время как простые случаи транслируются элементарно, по мере работы с транслированным кодом обнаруживается большое количество нюансов, существенно усложняющих процесс кодогенерации. Например, в C# порядок вычисления аргументов метода определён, а в C++ – нет. - Сложность поиска ошибок.
Отладка транслированного кода – отдельный вид искусства. Нюансы вроде описанного выше могут существенно влиять на работу программы, вызывая труднообъяснимые ошибки. С другой стороны, они могут оставаться незамеченными и долгое время присутствовать в виде скрытых багов. - Различия в системе управления памятью.
В C++ нет уборки мусора, и нам приходится тратить много сил на то, чтобы заставить транслированный код вести себя подобно оригиналу. - Необходимость дисциплины для программистов C#.
Программистам C# необходимо свыкнуться с ограничениями, налагаемыми процессом преобразования кода на C++. Есть несколько типов ограничений, с которыми им приходится сталкиваться:- Ограничения на версию языка, понимаемую нашим синтаксическим анализатором.
- Запрет на использование конструкций, в настоящее время не поддерживаемых транслятором (например, мы пока не умеем транслировать оператор
yield). - Ограничения, следующие из структуры транслированного кода (например, для любого поля ссылочного типа должен существовать ответ на вопрос о том, является ли данная ссылка сильной или слабой, что не всегда так для кода на C#).
- Ограничения, накладываемые языком C++ (например, в C# статические переменные не удаляются до завершения всех foreground-потоков).
- Большой объём работы.
Очевидно, что даже используемое нашими продуктами подмножество библиотеки .NET достаточно велико, и на реализацию всех классов и методов уходит много времени. - Особые требования к разработчикам..
Из-за того, с какими задачами мы работаем, на собеседованиях нам приходится задавать те самые «школьные» вопросы, которые так обижают многих программистов. Практика показывает, что человек, недостаточно любознательный, чтобы начать рассуждать о том, как устроен внутри операторusing, не справится с нашими задачами независимо от своего опыта по реализации рутинной бизнес-логики. Необходимость знать оба языка или готовность успешно разобраться в одним из них также снижает количество доступных кандидатов. С другой стороны, любители теории компиляторов или других экзотических дисциплин легко находят в проекте свою нишу. - Хрупкость системы.
Несмотря на наличие тысяч тестов и сотен тысяч строк кода, на котором тестируется транслятор, периодически возникают проблемы, когда изменения, внесённые одной командой, ломают процесс конвертации и/или компиляции у другой команды из-за редко используемых синтаксических конструкций или попросту разных стилей входного кода. - Высокий порог вхождения в проект.
Большинство наших задач требует глубокого анализа. Обилие подсистем и сценариев ведёт к ситуации, когда каждая новая задача требует длительного знакомства с новыми гранями проекта. Не всем разработчикам нравится, когда изучать продукт приходится раз за разом, многие чувствуют себя комфортнее в ситуации, когда вхождение случается лишь однажды. - Сложности с защитой интеллектуальной собственности.
Если код C# достаточно легко обфусцируется коробочными решениями, то в C++ для этого приходится прилагать дополнительные усилия, поскольку многие члены классов не могут быть удалены из заголовочных файлов без последствий. Трансляция обобщённых классов и методов в шаблоны также создаёт уязвимость, обнажая алгоритмы.
Несмотря на это, проект весьма интересен с технической стороны. Работа над ним позволяет многое узнать и многому научиться. Академичность задачи также способствует этому.
Резюме
В рамках работы над проектом нам удалось реализовать систему, которая решает интересную академическую задачу ради её прямого практического применения. Мы организовали ежемесячный выпуск библиотек компании Aspose на языке, для которого они первоначально не предназначались. Оказалось, что большинство проблем вполне решаемо, а получившееся решение – надёжно и практично.
В скором времени планируется публикация ещё двух статей. В одной из них будет подробно, с примерами, рассказано о том, как работает транслятор и как конструкции C# отображаются на C++. В другой речь пойдёт о том, как нам удалось обеспечить совместимость моделей памяти двух языков.
Мы постараемся ответить на все заданные вопросы. Если читатели проявят интерес к другим аспектам разработки транслятора кода, мы можем рассмотреть возможность написания дополнительных статей на эту тему.